聚合
如果你想用一种方式计算流的元素的合或者把它们组合成一个结果,你可以使用reduce方法.它接收一个二元函数并不断应用它,第一次的参数是是流的前两个元素,然后是第一次调用的结果和流的第三个元素,依次类推,直到流的最后.
1 | Stream<Integer> values = Stream.of(1, 2, 3, 4, 5); |
这种情况下,reduce计算的是Stream中的数字的和.这个方法返回的是一个Optional,因为Stream可能是空的.你其实可以使用values.reduce(Integer::sum)代替values.reduce((x, y) -> x + y).
一般来说,如果聚合方法有一个聚合操作op,那么该聚合会产生v0 op v1 op v2 op ...,其中的vi op vi+1表示函数调用op(vi,vi+1).这个操作应该是满足结合律的,也即是说这个操作和你组合元素的顺序无关,(x op y) op z = x op (y op z).这样就允许使用并行流进行有效的聚合.
在实践中,有很多有用的结合操作,例如和,积,字符串连接,最大值和最小值,并集和交集.减法是一个不满足结合律的操作的例子.例如,(6-3)-2≠6-(3-2).
通常,会有一个标识e使得e op x=x,你可以使用这个元素作为计算的起始.例如,在加法中,0就是这个标识e.然后调用reduce的第二种形式:
1 | Integer sum = values.reduce(0, Integer::sum); |
如果流是空的,这个标识值就会被返回.这样你就不需要处理Optional类了.现在假设你有一个包含多个对象的流,你想要对对象们的某个属性求和,比如流中字符串的总长.你不能使用简单形式的reduce方法,因为它需要的一个函数(T,T)->T,其中参数类型和返回值类型都必须是一样的,而现在的情况下,这两种类型是不同的,流的元素的类型是字符串,而累积结果的类型是整型.幸好有另一种形式的reduce可以处理这个情况.
首先,你要提供一个累加器函数(total,word)->total+word.length().这个函数会被重复的调用,形成累加值.但是当并行计算时,会有多个累加值,你需要把它们再累加起来.为了这一点,你需要提供第二个函数.完整代码:
1 | Integer result = words.reduce(0, (s, word) -> s + word.length(), (total, subtotal) -> total + subtotal); |
实践中,你可能不会大量使用ruduce方法,通常,更简单的方法是映射到一个数字流并使用它的方法来计算总和,最大值和最小值.在这个例子中,可以调用words.mapToInt(String::length).sum(),它更简单也更高效,因为它不涉及装箱拆箱.
收集结果
当你对一个流进行了处理,你通常想要看到结果而不是吧它们聚合成一个值.你可以调用iterator方法,生成一个旧式的迭代器用来访问元素.或者调用toArray获取流元素组成的一个数组.
因为在运行时产生一个泛型的数组是不可能的,表达式stream.toArray()返回的是一个Object[]数组.如果你想得到一个正确的类型的数组,传入数组的构造器引用:
1 | Stream<String> words = Stream.of("what", "which", "where"); |
现在假设你想要把结果收集到一个HashSet中,如果集合并行化了,你无法直接把元素放入到单个HashSet中,因为HashSet不是线程安全的.由于这个原因,你也不能使用reduce,每个块都需要一个空的HashSet,但reduce方法只让你提供一个标识值.可以使用collect,它有三个参数:
- 一个生成目标对象实例的生产者,比如,一个
HashSet的构造器. - 一个把元素添加到目标对象的累加器.例如,
add方法. - 一个把两个对象合成一个的组合器,如
addAll方法.
注意,目标对象不一定是集合,也可以是StringBuilder或一个跟踪数量和总和的对象.
下面是产生一个HashSet的collect的写法:
1 | HashSet<Integer> integers = nums.collect(HashSet::new, HashSet<Integer>::add, HashSet::addAll); |
实践中,你不需要这样写,因为有一个便利的Collector接口代替这三个函数,并且有包含了很多常用的收集器的类Collectors.把一个流收集到一个list或set,你只需简单的调用:
1 | List<Integer> result = nums.collect(Collectors.toList()); |
或
1 | List<Integer> result = nums.collect(Collectors.toSet()); |
如果你想要控制获得的set类型,可以像下面这样调用:
1 | TreeSet<Integer> result = nums.collect(Collectors.toCollection(TreeSet::new)); |
如果想要通过拼接把流中的所有字符串收集起来,你可以调用:
1 | String join = StreamFactory.stringStream().collect(Collectors.joining()); |
如果你想要在字符串之间加入分隔符,可以把它传入joining方法:
1 | String delimiter = StreamFactory.stringStream().collect(Collectors.joining(",")); |
如果流中包含的对象不是String类型的,你需要先把它们转换成字符串,像这样:
1 | String persons = StreamFactory.objectStream().map(StreamFactory.Person::toString) |
如果你想要对流进行聚合求和,平均值,最大值v,最小值,可以使用Collectors中的summarizing方法.这些方法接收一个可以把流中的对象映射到数字的函数,返回一个类型是(Int|Long|Double)SummaryStatistics的对象,它带有获取和,平均值,最大值,最小值的方法.
1 | IntSummaryStatistics statistics =words.collect(Collectors.summarizingInt(String::length)); |
到此为止,我们已经看到如果聚合和收集流中的值.但你可能只是想要打印它们或把它们放入数据库,你可以使用forEach方法:
1 | stream.forEach(System.out::println); |
你传入的这个函数会被应用到流中的每个元素上.在一个并行流中,你需要保证这个函数式可以被并发地执行的.
**在一个并行流上,元素可能会被以任意的顺序遍历,如果你想按照流中的属性执行,调用forEachOrdered.**当然,这样你就放弃了并行带来的好处.forEach和forEachOrdered方法都是终结操作,调用它们之后,你无法再使用流了.如果你想继续使用流,使用之前提到的peek.
将结果收集到Map
假设你有一个Person的流,你想把元素收集到一个Map以便可以使用它们的ID来进行查找.你可以使用Colletors.toMap方法,它有两个函数参数,分别用来生成map的键和值.例如:
1 | Map<Integer, String> idToName = people.collect(Collectors.toMap(Person::getId, Person::getName)); |
一般情况下,值应该是实际的元素,所以使用Function.identity()作为第二个参数:
1 | Map<Integer, Person> idToPerson = people.collect(Collectors.toMap(Person::getId, Function.identity())); |
如果多个元素有相同的键,那么收集器会抛出IllegalStateException异常.但你可以通过提供第三个函数参数重写这个行为.这个函数的参数是已有值和新的值,你可以返回它们中的一个或者根据它们另外产生一个值来返回.这里,我们构造一个map,对于系统的支持的所有语言,以其默认语言环境中的名字作为键,以其本地化的名字作为值.
1 | Stream<Locale> locales = Stream.of(Locale.getAvailableLocales()); |
但是,如果我们希望知道指定国家的所有语言,那么我们需要一个Map<String,Set<String>>对象.首先,我们把每种语言存到单个集中,当发现指定国家的新的语言时,我们就将已有值和新值组合成一个新的集合.
1 | Map<String, Set<String>> countryLanguageSets = locales |
如果你想要的是一个TreeMap,那么你需要提供一个构造器引用作为第四个参数.
1 | TreeMap<Integer, Person> id2Person = people |
对于上面的三种toMap方法,都有对应的toConcurrentMap方法,用来产生一个并发map.在并行收集过程中应该只使用一个并发的map.当在并行流中使用并发map时,一个共享的map要比合并map更高效,当然,使用共享map无法保证顺序.
分组和分片
在之前的章节中,我们看到怎么收集特定国家的所有语言.但是,那个代码很冗长.对有共同特性的值进行分组是是很常见的需求,groupingBy方法就是专门用于分组的.
还是对国家语言分组的问题,首先,我们构建这样一个map:
1 | Map<String, List<Locale>> country2Locales= locales.collect(Collectors.groupingBy(Locale::getCountry)); |
函数Local::getCountry是进行分组的分类函数.现在可以查找指定国家中所有语言,例如:
1 | List<Locale> swissLocales = country2Locales.get("CH"); |
当分类函数是一个predicate函数时,流元素会被分为两组:一组是函数会返回true的元素,另一组是返回false的元素.在这种情况下,使用partitionBy方法.例如,把所有语言环境分为两组,一组是使用英语一组使用的是其他语言:
1 | Map<Boolean, List<Locale>> englishAndOtherLocales = locales.collect(Collectors.partitioningBy(l -> l.getLanguage().equals("en"))); |
groupingBy方法生成的map的值是list,如果你想要使用某种方式处理这些list的时候,你要提供一个downstream的收集器.例如,你想要set而不是list,你可以使用Collectors.toSet.
1 | Map<String, Set<Locale>> countryToLocaleSet = locales.collect(groupingBy(Locale::getCountry, toSet())); |
还有若干其他的收集器可以用于分好组的元素的downstream的处理.counting产生被收集的元素的个数,例如:
1 | Map<String, Long> countryToLocaleCounts = locales.collect(groupingBy(Locale::getCountry, counting())); |
summing(Int|Long|Double)接受一个函数参数,应用这个函数到downstream的元素,生成它们的合,例如:
1 | Map<String, Integer> stateToPopulation = cities.collect(groupingBy(City::getState, summingInt(City::getPopulation))); |
maxBy和minBy接收一个比较器并产生downstream元素的最大值和最小值.例如:
1 | Map<String, Optional<City>> stateToLargestCity = cities |
mapping应用一个函数到downstream,它还需要另一个收集器处理之前的结果.还记得上一个章节中的收集国家的所有语言到一个set的问题吗?mapping方法可以提供一个更加漂亮的解决方案:
1 | Map<String, Set<String>> countryToLanguages = locales |
如果分组或映射函数的返回值类型是int,long,或double,你可以收集元素到一个统计对象,它在之前章节就出现过.例如:
1 | Map<String, IntSummaryStatistics> stateToCityPopulationSummary = cities |
最后,reducing方法可以对downst的元素应用一个聚合函数.它有三种形式:reducing(binaryOperation),reducing(identity,binaryOperation)和reducing(identity,mapper,binaryOperation),这其实和reduce的三种形式是对应的.下面是一个获取每个州的所有城市名以逗号分隔的字符串:
1 | Map<String, String> stateToCityNames = cities.collect(groupingBy(City::getState, reducing("", City::getName, (s, s2) -> s |
和reduce一样,reducing用的并不多.这个例子中,我们可以更自然的达到目的:
1 | stateToCityNames = cities.collect(groupingBy(City::getState, mapping(City::getName, joining(",")))); |
显然,downstream收集器会产生非常复杂的代码.显然,使用downstream收集器会产生非常复杂的代码.所以,你应该只在处理groupingBy或partitionBy产生的分组的时候使用它们,其他情况,只需要使用诸如map,reduce,count,max或min这些简单的方法即可.
原生类型流
目前为止,我们都是把整数收集到一个Stream<Integer>,尽管把每个整形放入包装对象显然是低效的做法.其他原始类型也是一样的.为此,Stream API提供了特化类型IntStream,LongStream和DoubleStream,它们直接存储原始类型值,不需要包装.下面是对应关系:
- 存放short、char、byte、int和boolean类型的值,使用
IntStream - 存放float和double类型的值,使用
DoubleStream. - 存放long类型的值,使用
LongStream.
要创建一个IntStream,可以调用IntStream.of和Arrays.stream方法:
1 | IntStream stream = IntStream.of(1, 2, 3, 5); |
和对象流一样,IntStream和LongStream提供了静态方法range和rangeClosed来生成步数为1的数列.
1 | IntStream zeroToNinetyNine = IntStream.range(1, 100); |
CharSequnces有两个方法codePoints和chars分别生成Unicode字符的IntStream和UTF-16编码单元的IntStream.
1 | String sentence = "\uD835\uDD46 is the set of octonions"; |
当你有一个对象流,你可以使用mapToInt,mapToDouble,mapToLong方法把它转换成原生类型流.例如:
1 | Stream<String> words = StreamFactory.stringStream(); |
使用boxed方法把原生类型流转换为对象流:
1 | Stream<Integer> integers = IntStream.range(0, 100).boxed(); |
一般而言,原生类型流的方法和对象流的方法是类型的,下面是原生类型流和对象流最显著的一些区别:
- 原生类型流的
toArray返回原生类型数组,而对象流的toArray方法返回的是对象数组 - 原生类型流的生成可选结果的方法返回的是
OptionalInt、OptionalLong或OptionalDouble.这些类和Optional类相似,但是它们有getAsInt、getAsLong和getAsDouble来代替get方法. - 原生类型流有
sum,average,max和min方法,对象流没有 summaryStatistics方法生成一个类型是IntSummaryStatistics、LongSummaryStatistics和DoubleSummaryStatistics的对象,通过它们可以获取流的总和,平均值,最大值和最小值.
Random类的ints,longs和doubles方法返回随机数的原生类型流,但要注意,这些流是无限流.
并行流
流使对大量运算并行化非常容易.这一过程基本是自动的,但你也需要遵守一些规则.首先,你要有一个并行流.除了Collection.parallelStream方法,流操作生成的都是顺序流.parellel方法可以把任意顺序流转换成并行流.例如:
1 | Stream<Integer> parallelIntegers = Arrays.asList(1, 2).parallelStream(); |
只要流是处于并行模式,当执行终结方法的时候,所有的中间流操作都会被并行化.
并行化的目的,是希望能得到和顺序执行一样的结果,所以操作必须是无状态和顺序无关,这很重要.
下面有一个反例,加上你要计算字符串流中短单词的个数:
1 | int[] shortWords = new int[12]; |
这是非常糟糕的代码.传递给forEach的函数会在多个线程中并发执行,来更新一个共享的数组,这是典型的竞态条件如果你将这段代码多运行几次,很可能每次都会得到不同的结果,而且没有一个是对的.
你需要确保传递给并行流操作的函数式线程安全的.在我们这个例子中,你可以使用一个AtomicInteger的数组作为计数器,或者使用Stream API提供的方法,对字符串按长度分组再计数.
默认情况下,从有序集合(数组或列表),范围值,生成器以及迭代器,或者Stream.sorted所产生的流,都是有序的.对这些流操作的结果也是按照顺序累计的,是完全可预测的.如果你只需相同的操作两次,得到的结果也会是相同的.
顺序并不会妨碍并行.例如,当计算stream.map(fun)时,流会分为n块,每一块都会被并行处理,然后在按照顺序将结果组合起来.
当不考虑顺序时,某些操作可能会更加高效地并行化.通过调用stream.unordered方法,你可以表明你不关心顺序,stream.distinct就是一个可以从中受益的操作.对于有序流,distinct方法会保留所有的相等元素的第一个,这样会阻碍并行,因为处理某块流的线程只有在之前的元素块处理完之后,才知道应该丢弃哪些元素.如果允许保留任意的唯一元素,所有的块都可以并行处理(使用一个共享的set)
你还可以通过放弃有序来加快limit方法的速度.如果你想要一个流中任意n个元素,可以这样写:
1 | Stream<T> sample = stream.parallel().unordered().limit(10); |
之前说过,合并map的开销很大,所以,Collectors.groupingByConcurrent使用一个共享的并发map.显然,要从并行计算中获益,map中的值的顺序将无法保证与流中的顺序一致.即使是对于一个有序的流,该收集器也具有无序的天性,因此你不需要标记这个流是无序的.但是,你还是需要将流标记为并行模式:
1 | ConcurrentMap<String, List<City>> re = cities.parallel().collect(Collectors.groupingByConcurrent(City::getState)); |
注意,当你执行一个流操作的时候,你并不会修改流底层的集合(即使这个操作是线程安全的).准确一点说,由于中间流操作是延迟执行的,所以在终结操作执行的之前改变集合是可能的.例如,下面的代码是正确的:
1 | Stream<String> words = Stream.of("BEGIN","RUNNING"); |
但下面的代码是不正确的:
1 | words = wordList.stream(); |
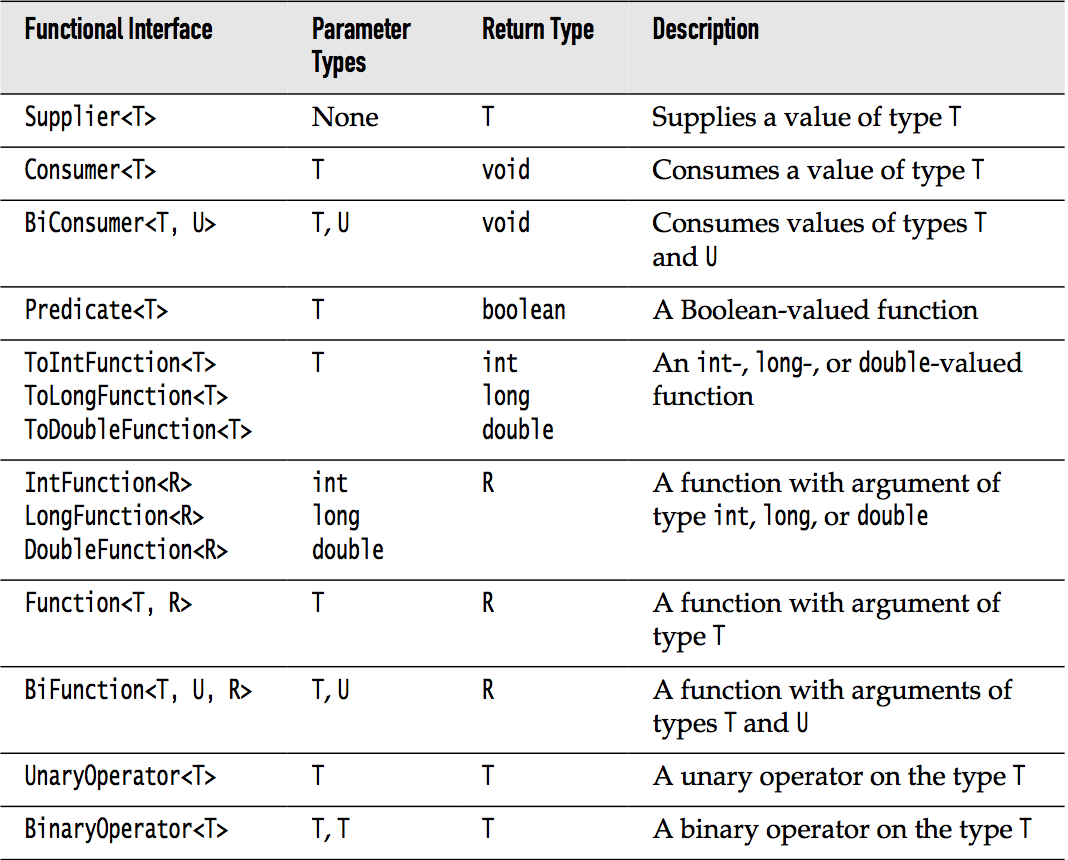
函数式接口
在本章中,已经看了很多参数为函数的方法.例如Stream.filter方法:
1 | Stream<T> filter(Predicate<? super T> predicate); |
查看javadoc,发现Predicate是一个函数式接口,只包含一个返回boolean的非默认方法:
1 | boolean test(T t); |
在实际开发中,一般会传递lambda或者方法引用到filter方法.所以这个方法的名字并不重要,重要的是返回的是boolean值.你在看文档的时候,只要记住Predicate是一个返回boolean值的函数就行.
下面的图列举了作为Stream和Collectors方法参数的函数式接口: